
需求描述
最近开发提了这样一个需求:
BEGIN; UPDATE products SET quantity=quantity-1 WHERE product_id=123456; SELECT quantity FROM products WHERE product_id=123456; COMMIT; |
在一个事务中UPDATE之后需要SELECT出更新后的值,希望在MySQL中能只使用一条SQL就能做到,这样既可以方便开发,又可以大大减小事务处理时间,其实这个需求在Oracle/PostgreSQL中已经有相应的语法支持,PostgreSQL UPDATE,实现这个需求还有一个前提:不修改MySQL服务器/客户端协议,能够兼容JDBC
最初的想法是直接采用UPDATE…RETURNING语法,上述事务中的两条SQL只需要一条就能实现功能:
UPDATE products SET quantity=quantity-1 WHERE product_id=123456 RETURNING quantity; |
然而mysql-connector并没有给我们留下发挥空间:
java中Statement执行sql主要有两个方法:Statement.executeQuery和Statement.executeUpdate,前者的返回结果是ResultSet,主要用于执行SELECT,后者只返回int,主要用于执行DDL/DML,我们需要返回ResultSet,那么只能调用executeQuery接口,然而用一条UPDATE语句执行时会报错,原因是mysql-connector中的StatementImpl类在实现executeQuery方法时对传入sql做检查,具体函数:checkForDml
protected void checkForDml(String sql, char firstStatementChar) throws SQLException { if ((firstStatementChar == 'I') || (firstStatementChar == 'U') || (firstStatementChar == 'D') || (firstStatementChar == 'A') || (firstStatementChar == 'C') || (firstStatementChar == 'T') || (firstStatementChar == 'R')) { String noCommentSql = StringUtils.stripComments(sql, "'\"", "'\"", true, false, true, true); if (StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "INSERT") //$NON-NLS-1$ || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "UPDATE") //$NON-NLS-1$ || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "DELETE") //$NON-NLS-1$ || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "DROP") //$NON-NLS-1$ || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "CREATE") //$NON-NLS-1$ || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "ALTER") || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "TRUNCATE") || StringUtils.startsWithIgnoreCaseAndWs(noCommentSql, "RENAME")) { //$NON-NLS-1$ throw SQLError.createSQLException(Messages.getString("Statement.57"), //$NON-NLS-1$ SQLError.SQL_STATE_ILLEGAL_ARGUMENT, getExceptionInterceptor()); //$NON-NLS-1$ } } } |
因此考虑扩展语法时在前面加上SELECT,如:
SELECT field1,field2,... FROM UPDATE... |
然后就可以走executeQuery接口了,并且返回的是ResultSet.
mysql_update
在前一篇博客中介绍了UPDATE语法的SQL解析过程和解析结果:
set左值集合:lex->select_lex.item_list
set右值集合:lex->value_list
where条件:lex->where
下面分析一下mysql_update的执行过程:
mysql_update |-->open_tables |-->lock_tables |-->mysql_prepare_update // 将set左值集合fields的各个Item_field对象中的field指向TABLE中field数组中的对应地址, // 当通过handler从存储引擎层获取到数据后,TABLE中的field数组会被填充, // setup_fields后,若更新fields将导致TABLE中field被更新 |-->setup_fields_with_no_wrap(thd, 0, fields, MARK_COLUMNS_WRITE, 0, 0) // 将set右值集合values的各个Item_field对象中的field指向TABLE中field数组中的对应地址, // 填充模式为MARK_COLUMNS_READ,values中的每一个对象其实是一棵表达式树 |-->setup_fields(thd, 0, values, MARK_COLUMNS_READ, 0, 0) |-->open_cached_file //使用IO_CACHE缓存从存储引擎层读到的满足where条件的记录 |-->init_read_record //根据对where条件的分析初始化扫描物理记录的方法 |-->while(info.read_record(&info)) //读取物理记录,保存到IO_CACHE中 |-->found++ |-->end_read_record |-->reinit_io_cache(&tempfile,READ_CACHE,0L,0,0) //开始从IO_CACHE中读取需要更新的记录 |-->while(info.read_record(&info)) // read_record会将结果读取的结果填充到table->record[0]中 |-->store_record(table,record[1]) // 这一步很关键,读取的每一行记录被解析填充到TABLE结构中的各个field中了,values中的每个Item_field // 通过setup_fields函数,将其field成员直接指向了TABLE中对应的field地址了,setup_fields(values) // 的方式是MARK_COLUMNS_READ,setup_fields(fields)的方式是MARK_COLUMNS_WRITE, 因此计算set右值出来 // 之后赋值给对应的set左值,这样就将TABLE中各个field更新了 |-->fill_record_n_invoke_before_triggers(thd, fields, values, 0, table->triggers, TRG_EVENT_UPDATE) // 调用存储引擎层的update函数,更新一行记录 |-->file->ha_update_row(table->record[1], table->record[0]) |-->if (error != HA_ERR_RECORD_IS_THE_SAME) updated++ |-->end_read_record |-->thd->binlog_query |-->my_ok |
需要修改的地方
1. 在sql/sql_yacc.yy中增加语法规则
这里遇到了很多问题,源于理论和实践还不够,不过最终还是完成了,新增语法:
GET expr1,expr2,...FROM UPDATE... |
为什么是GET,而不是之前的SELECT? 因为会与SELECT expr1,expr2,…FROM…规则产生冲突,因此换成了GET(已更新!见文章末尾),代码中增加:
sql/sql_lex.h文件
symbols数组中增加GET关键字定义:
{ "GET", SYM(GET_SYM)}, |
sql/sql_yacc.yy文件
a)增加token定义:
%token GET_SYM |
b)增加规则:getupdate
get_update:
GET_SYM
{
LEX *lex= Lex;
mysql_init_select(lex);
}
select_item_list FROM
UPDATE_SYM
{
LEX *lex= Lex;
lex->sql_command= SQLCOM_UPDATE;
lex->duplicates= DUP_ERROR;
lex->return_update= true;
lex->real_query_start= YYLIP->get_tok_start() - YYTHD->query();
lex->return_update_list.swap(Select->item_list);
Select->item_list.empty();
}
opt_low_priority opt_ignore table_ident
SET update_list
{
if (!Select->add_table_to_list(YYTHD, $9, NULL,
TL_OPTION_UPDATING,
TL_READ_DEFAULT,
MDL_SHARED_READ))
MYSQL_YYABORT;
Select->set_lock_for_tables($7);
}
where_clause opt_order_clause delete_limit_clause {}
; |
c) 在statement规则中增加get_update子规则(get_update需要规约到statement规则)
| get_update |
2. 解析语法并保存select field列表
select_item_list和update_list都会把解析得到的Item放到lex->select_lex.item_list中,因此在LEX结构体中新增了三个成员
+ /* + Impliment Oracle/PostgreSQL's + "UPDATE...RETURNING..." as "GET...UPDATE..." + */ + bool return_update; + List return_update_list; + uint32 real_query_start; |
get_update规则在解析到update_list之前,会将已经解析得到的select_item保存到lex->select_lex.item_list中,而之后的update_list规则也会将set左值保存在其中,因此在解析update_list之前将其移到return_update_list后并清空列表,这样就可以在整个规则解析完成后,分别得到select fields和update fields,我们不希望由于新语法的添加影响到复制功能,因此增加real_query_start记录真正update query的起始位置,正确写statement格式binglog
3. 根据更新后的行记录填充select field列表
4. 增加update返回客户端结果集的逻辑
整个设计写得差不多了,3和4没有什么好写的,很多细节的东西,得到了select fields后以MARK_COLUMNS_READ调用setup_fields就可以根据更新后行信息计算出结果,发给客户端就OK,稍后放出patch
实现结果
mysql> show create table tt\G *************************** 1. row *************************** Table: tt Create Table: CREATE TABLE `tt` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=gbk 1 row in set (0.00 sec) mysql> select * from tt; +----+------+------+------+ | id | a | b | c | +----+------+------+------+ | 1 | 1 | 2 | 3 | | 2 | 2 | 3 | 4 | | 3 | 3 | 4 | 5 | | 4 | 4 | 5 | 6 | | 5 | 5 | 6 | 7 | | 6 | 6 | 7 | 8 | | 7 | 6 | 1 | 9 | +----+------+------+------+ 7 rows in set (0.00 sec) mysql> get NOW() as time, a+5 as a5, b from update tt set a=7, b=b+7 where id=7; +---------------------+------+------+ | time | a5 | b | +---------------------+------+------+ | 2013-05-24 18:08:54 | 12 | 8 | +---------------------+------+------+ 1 row in set (0.01 sec) mysql> select * from tt; +----+------+------+------+ | id | a | b | c | +----+------+------+------+ | 1 | 1 | 2 | 3 | | 2 | 2 | 3 | 4 | | 3 | 3 | 4 | 5 | | 4 | 4 | 5 | 6 | | 5 | 5 | 6 | 7 | | 6 | 6 | 7 | 8 | | 7 | 7 | 8 | 9 | +----+------+------+------+ 7 rows in set (0.00 sec) |
性能测试
mysql的CLIENT_MULTI_STATEMENTS提供了执行多stmt支持,本文实现的get update方案相对于CLIENT_MULTI_STATEMENTS在理论上减小了sql parse的代价
a) 数据准备
mysql> show create table t\G *************************** 1. row *************************** Table: t Create Table: CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `num` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16472591 DEFAULT CHARSET=gbk 1 row in set (0.00 sec) mysql> select count(*) from t; +----------+ | count(*) | +----------+ | 16472590 | +----------+ 1 row in set (3.47 sec) |
b) 测试方法
multi_statment: >id_rand=rand() % update_rows >update t set num=num+1 where id=id_rand; select num from t where id=id_rand; get_update: >id_rand=rand() % update_rows >get num from update t set num=num+1 where id=id_rand; |
c) 测试结果
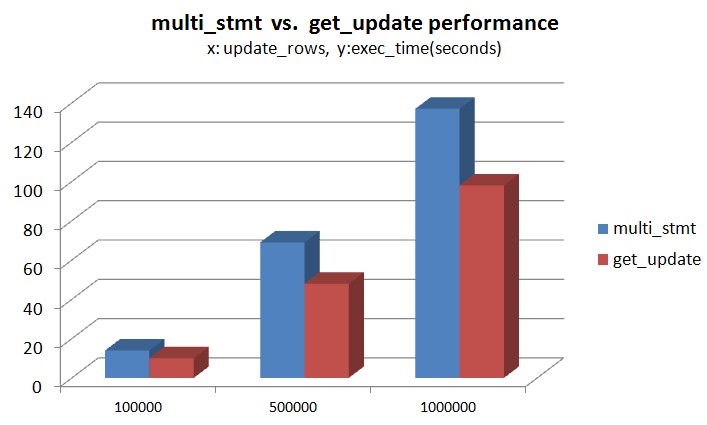
d) 测试程序
UPDATED!
patch下载:get_update.patch
UPDATED!!
经过持续学习和尝试,终于将GET替换成SELECT了,最新patch: select_update.patch